

手机站

新浪微博
微信公众号
手机站
新浪微博
微信公众号

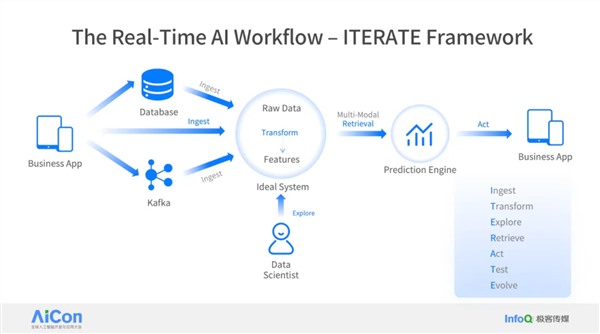
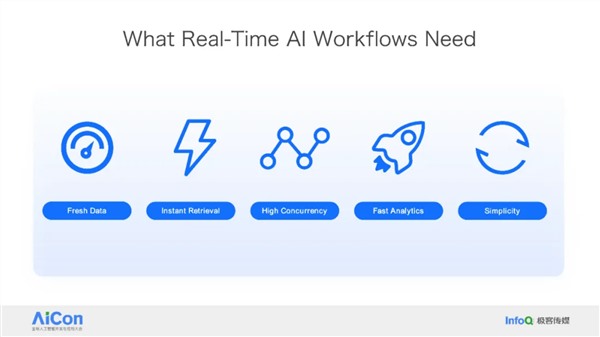
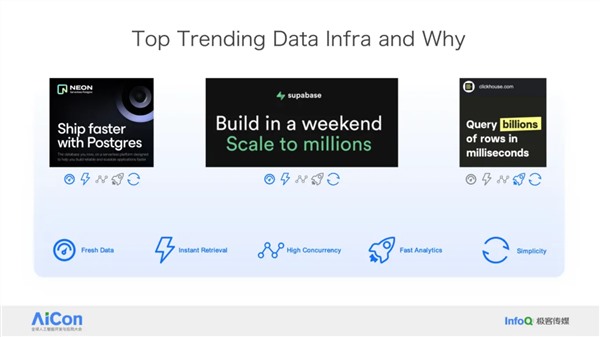
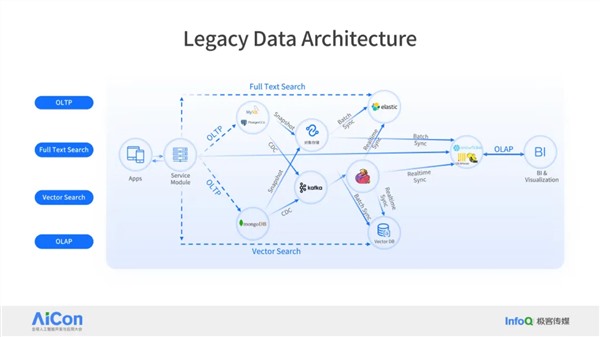
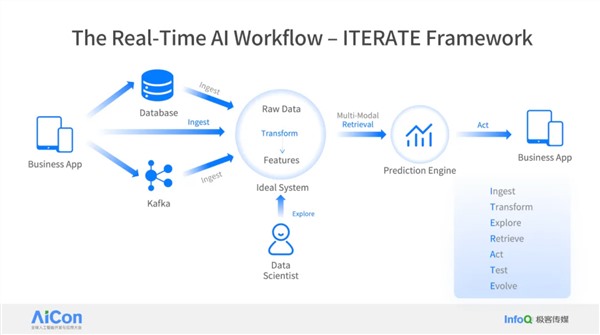
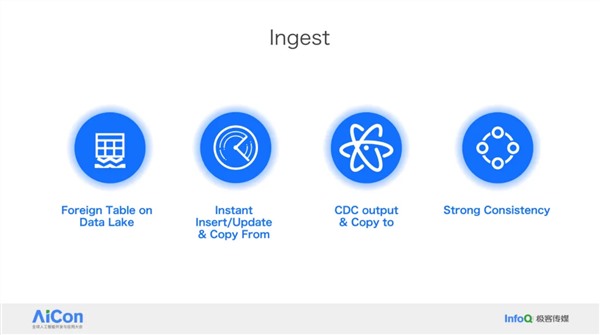
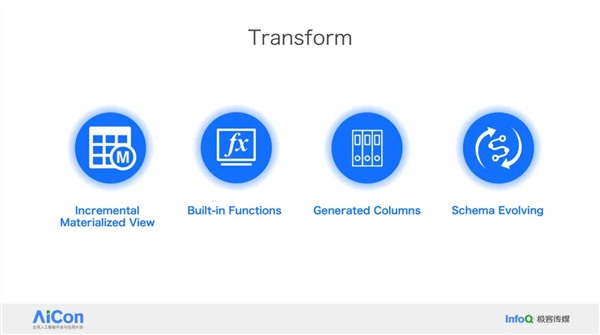
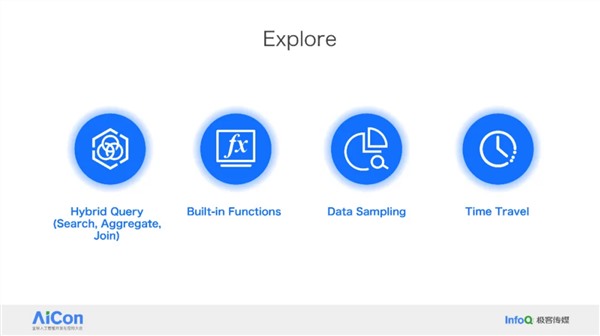


作者简介:
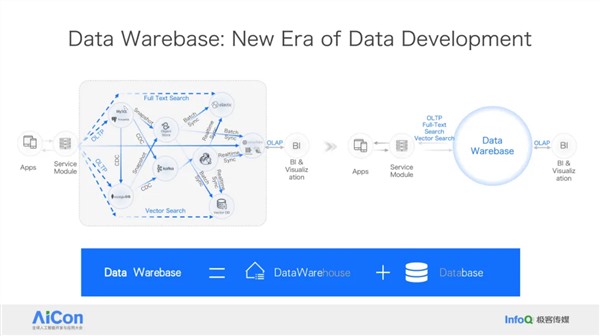
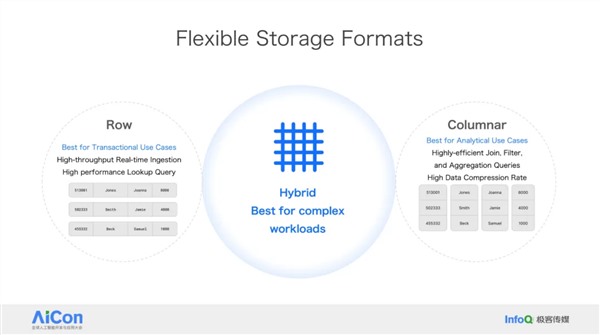
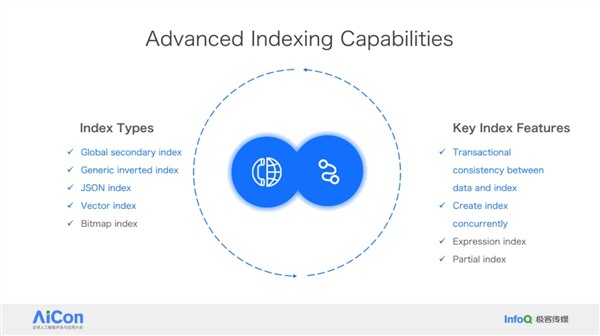
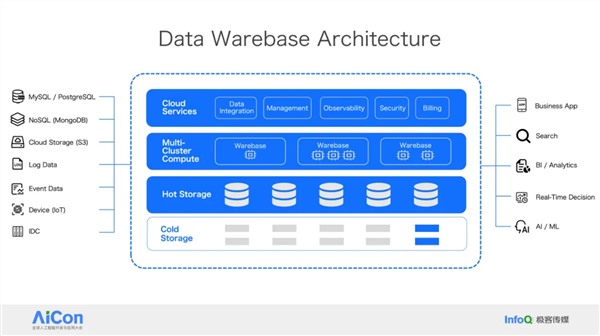
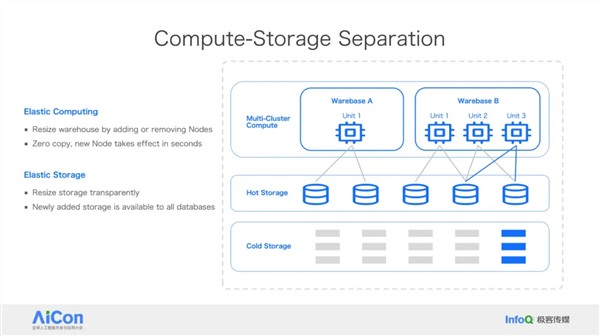
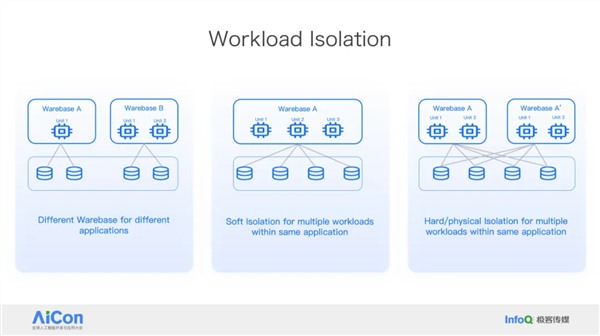
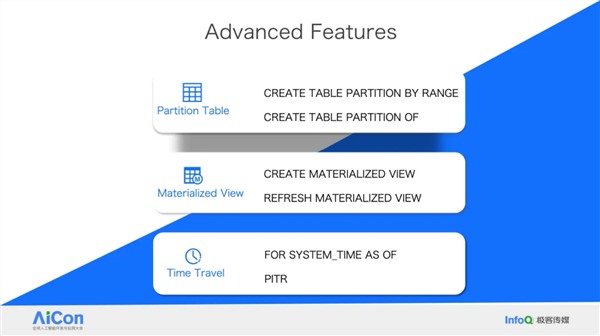
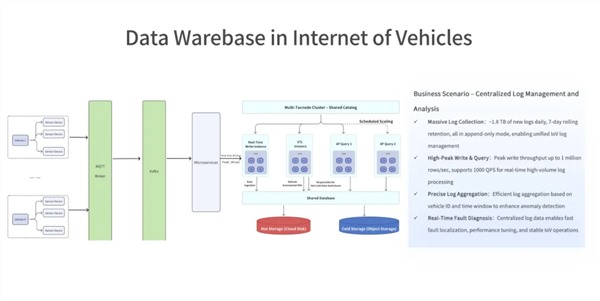
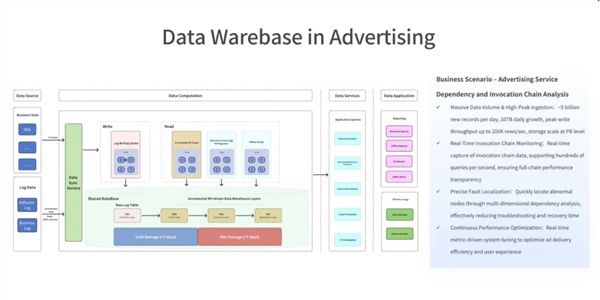
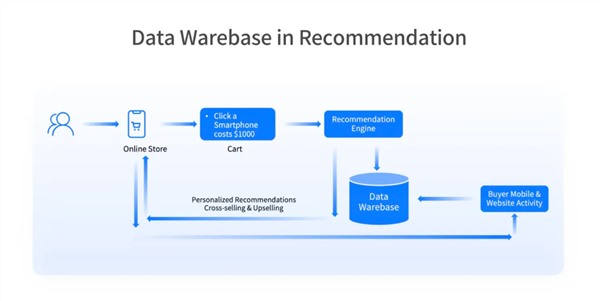
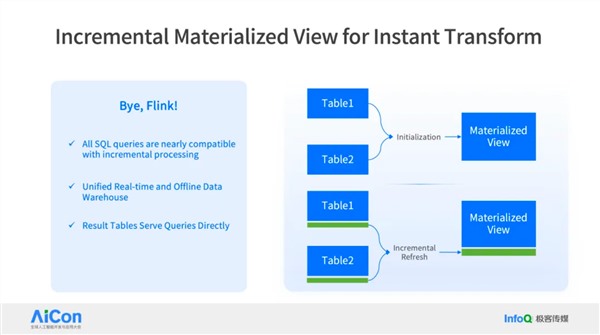
王绍翾,ProtonBase创始人兼CEO。曾在Facebook负责在线基础设施开发,并深度参与了Memcache,RocksDB和自研分布式图数据库TAO的开发,该数据库支撑了Facebook每秒几十亿次的海量数据查询。2015年加入阿里巴巴,先后负责两项核心工作:一是用Flink打造了搜索推荐相关的数据处理与AI机器学习平台,二是负责达摩院机器智能工程团队,包括视觉/语音/NLP等AI场景的模型训练,推理,以及向量检索技术。2021年开始创业,创立“小质科技”,推出了自研产品ProtonBase,一款融合数据库与数据仓库能力于一体的新一代Data Warebase(Data Warehouse+Database)。






【环球科技网】随着数字化转型步伐的加速,数字化的作用不断提升,IT基础架构的重要性也随之水涨船高。企业都希望拥有一套稳定、易管、灵活扩展的IT基础架构,以应对日益复杂且快速变化的业务需求。 然而,现实和理想之间往往存在巨大的落差…… 现实之中的数据中心大... [阅读]
【环球科技网】关内容设计、开发,被工信部纳入人才培养工程课程体系。至2024年9月底,共有超过20000人参加培训,16000余人通过考试并获得“软件工程造价师证书”。软件工程造价师熟练掌握了软件开发、运维等信息化项目投入工作量及工程造价的估算方法,能够相对科学合理地为信息化项目的概算编制、预算审批、工程结算... [阅读]
11月26日,Chiphell论坛消息人士panzerlied昨今两日在回复有关英伟达GeForce RTX 5090 D显卡的帖子时表示“5090和 5090D在硬件上没有什么区别”,并认为两者在同频下游戏性能“没啥区别”。 这位消息人士还提到,英伟达将在... [阅读]
【环球科技网】11月15日, 以“以智能,致世界”为主题的操作系统大会2024在北京召开,本次大会由openEuler社区、全球计算联盟共同主办,旨在汇聚全球产业界力量,推动基础软件根技术持续创新,共建全球开源新生态。 openEuler开源五年,在商业、技术及生态上全面发展,202... [阅读]





2026-06-12
2026-06-04
2026-06-03
2026-06-02
2026-05-22




2026-06-12
2026-06-04
2026-06-03
2026-06-02
2026-05-22







